6. Time Series#
Warning
Under construction
This notebook comprises various text and code snippets for generating plots and other content for the lectures corresponding to this topic. It is not a coherent set of lecture notes. Students should refer to the actual lecture slides available on Blackboard.
Note
These (and most other) notes derive heavily from DelSole and Tippett’s fantastic textbook, Statistical Methods for Climate Scientists.
6.1. (notebook preliminaries)#
%matplotlib inline
%config InlineBackend.figure_format = "retina"
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy
import statsmodels.api as sm
import holoviews as hv
hv.extension('bokeh')
import panel as pn
pn.extension()


import puffins as pf
from puffins import plotting as pplt
# Make fonts bigger for slides
plt.rcParams['font.size'] = 16
import xarray as xr
# Load the data
filepath_in = "../data/central-park-station-data_1869-01-01_2023-09-30.nc"
ds_cp_day = xr.open_dataset(filepath_in)
# Clean: drop all 0 values of the temperature fields which are (mostly) spurious
for varname in ["temp_avg", "temp_min", "temp_max"]:
ds_cp_day[varname] = ds_cp_day[varname].where(ds_cp_day[varname] != 0.)
ds_cp_mon = ds_cp_day.resample(dict(time="1M")).mean()
ds_cp_ann = ds_cp_day.groupby("time.year").mean()
6.2. Deterministic and random components#
Often, we split timeseries (\(X_t\)) into deterministic (\(\mu_t\)) and random (\(\epsilon_t\)) parts:
Example deterministic parts: diurnal cycle, seasonal cycle, tides
What’s the deterministic part for your timeseries of interest?
Depends on the physical mechanisms governing the system! Usuallylly, from data we can only estimatee deterministic componenth \(\hat\mu_t\) 𝑡 (note the ht)
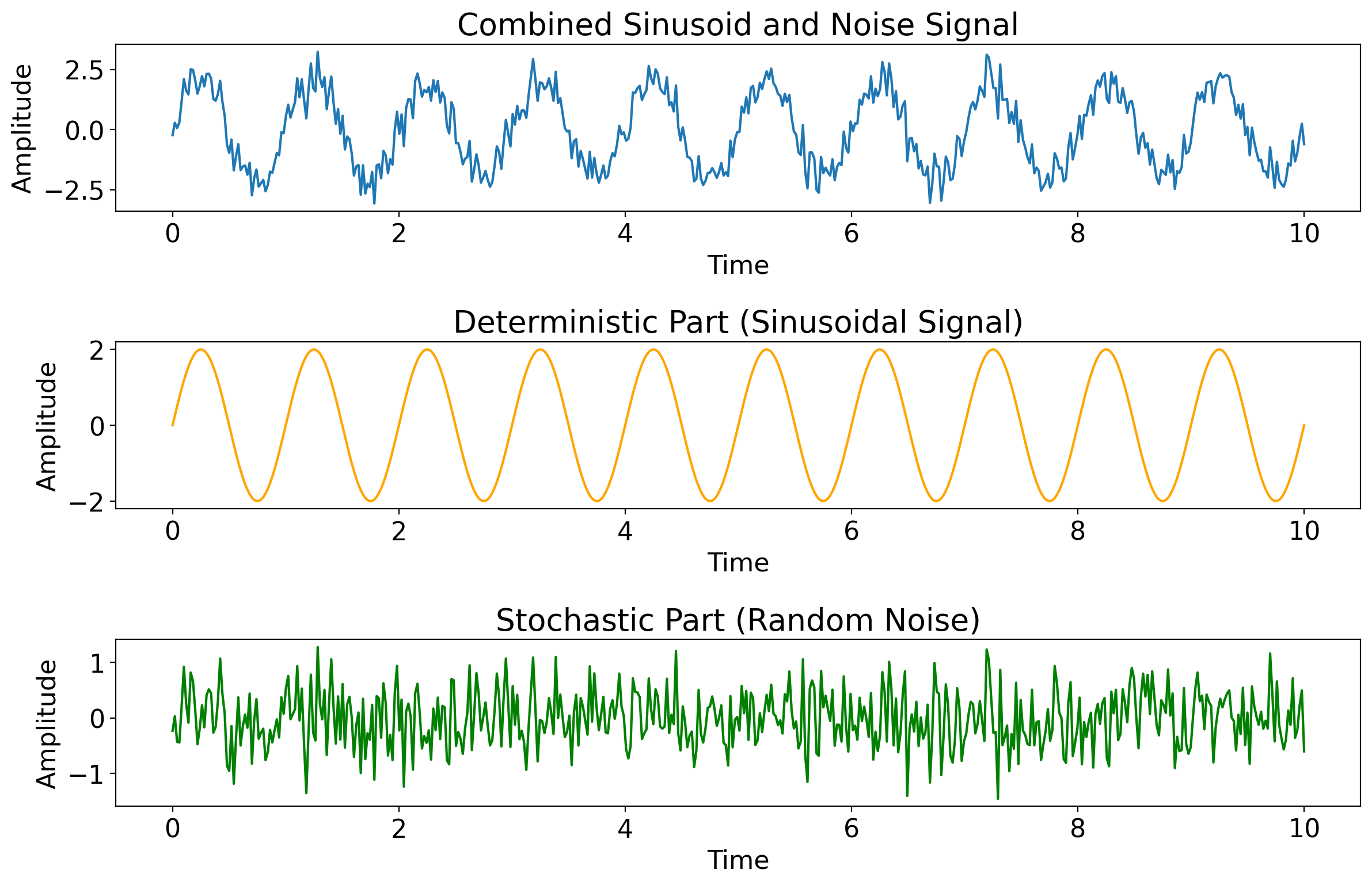
Next: an example time series generated by adding small-amplitude random noise to a repeated sinusoid.
# Time array
t = np.linspace(0, 10, 500)
# Sinusoidal component (deterministic part)
amplitude = 2
frequency = 1
sinusoid = amplitude * np.sin(2 * np.pi * frequency * t)
# Random noise component (stochastic part)
noise_amplitude = 0.5
noise = noise_amplitude * np.random.normal(size=t.shape)
# Combined signal
combined_signal = sinusoid + noise
# Plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 8))
# Combined signal
axs[0].plot(t, combined_signal, label='Combined Signal')
axs[0].set_title('Combined Sinusoid and Noise Signal')
# Sinusoidal part
axs[1].plot(t, sinusoid, label='Sinusoidal Signal', color='orange')
axs[1].set_title('Deterministic Part (Sinusoidal Signal)')
# Random noise part
axs[2].plot(t, noise, label='Random Noise', color='green')
axs[2].set_title('Stochastic Part (Random Noise)')
# Common labels
for ax in axs:
ax.set_xlabel('Time')
ax.set_ylabel('Amplitude')
plt.tight_layout()
plt.show()
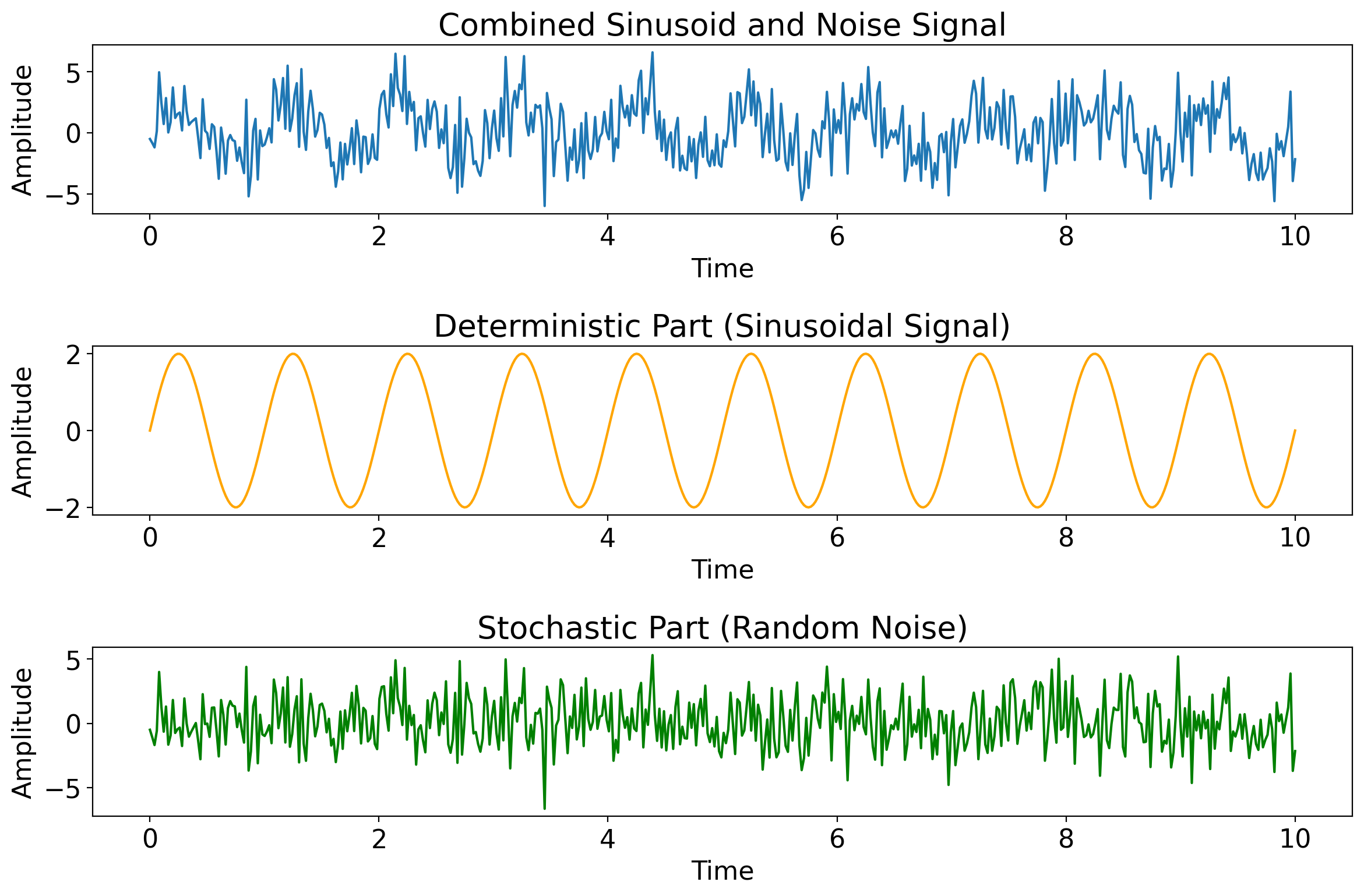
Next images: as the noise amplitude increases relative to the deterministic component, the deterministic part becomes increasingly hard to discern from the full timeseries.
import matplotlib.pyplot as plt
import numpy as np
# Time array
t = np.linspace(0, 10, 500)
# Sinusoidal component (deterministic part)
amplitude = 2
frequency = 1
sinusoid = amplitude * np.sin(2 * np.pi * frequency * t)
# Random noise component (stochastic part)
noise_amplitude = 2
noise = noise_amplitude * np.random.normal(size=t.shape)
# Combined signal
combined_signal = sinusoid + noise
# Plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 8))
# Combined signal
axs[0].plot(t, combined_signal, label='Combined Signal')
axs[0].set_title('Combined Sinusoid and Noise Signal')
# Sinusoidal part
axs[1].plot(t, sinusoid, label='Sinusoidal Signal', color='orange')
axs[1].set_title('Deterministic Part (Sinusoidal Signal)')
# Random noise part
axs[2].plot(t, noise, label='Random Noise', color='green')
axs[2].set_title('Stochastic Part (Random Noise)')
# Common labels
for ax in axs:
ax.set_xlabel('Time')
ax.set_ylabel('Amplitude')
plt.tight_layout()
plt.show()
import matplotlib.pyplot as plt
import numpy as np
# Time array
t = np.linspace(0, 10, 500)
# Sinusoidal component (deterministic part)
amplitude = 2
frequency = 1
sinusoid = amplitude * np.sin(2 * np.pi * frequency * t)
# Random noise component (stochastic part)
noise_amplitude = 4
noise = noise_amplitude * np.random.normal(size=t.shape)
# Combined signal
combined_signal = sinusoid + noise
# Plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 8))
# Combined signal
axs[0].plot(t, combined_signal, label='Combined Signal')
axs[0].set_title('Combined Sinusoid and Noise Signal')
# Sinusoidal part
axs[1].plot(t, sinusoid, label='Sinusoidal Signal', color='orange')
axs[1].set_title('Deterministic Part (Sinusoidal Signal)')
# Random noise part
axs[2].plot(t, noise, label='Random Noise', color='green')
axs[2].set_title('Stochastic Part (Random Noise)')
# Common labels
for ax in axs:
ax.set_xlabel('Time')
ax.set_ylabel('Amplitude')
plt.tight_layout()
plt.show()
The difference between the full time series and the estimated deterministic part is the anomaly, denoted \(X'_t\):
The anomaly \(X'_t\) differs from the random part \(\epsilon_t\) because the anomaly uses the estimated deterministic component \(\hat\mu_t\), whereas the random part \(\epsilon_t\) uses the true deterministic component.
6.3. Stationarity#
Strictly stationary process: one satisfying
for any timesteps \(x_{t_1},x_{t_2},\dots,x_{t_K}\) and any shift \(h\).
6.4. Serial dependence#
If two
6.4.1. Example#
import numpy as np
import holoviews as hv
import panel as pn
from statsmodels.tsa.arima_process import ArmaProcess
hv.extension('bokeh')
# Function to generate an AR(1) process
def generate_ar1_process(phi, size=100):
# Define AR(1) process with no MA component
ar = np.array([1, -phi])
ma = np.array([1])
AR_object = ArmaProcess(ar, ma)
return AR_object.generate_sample(nsample=size)
# Create the interactive plot
def interactive_autocorrelation(phi):
# Generate the time series
time_series = generate_ar1_process(phi)
# Create the Holoviews plot
hv_plot = hv.Curve(time_series).opts(width=800, height=400, title=f"AR(1) Time Series with phi={phi}")
return hv_plot
# Slider for the phi coefficient
phi_slider = pn.widgets.FloatSlider(name='Autocorrelation Coefficient (phi)', start=-0.99, end=0.99, step=0.01, value=0.5)
# Interactive function to update plot based on slider value
@pn.depends(phi=phi_slider)
def update_plot(phi):
return interactive_autocorrelation(phi)
# Panel layout
pn.Column(
pn.Row(phi_slider),
update_plot
).servable()
6.4.2. Effective degrees of freedom given serial correlation#
In short, when it comes to hypothesis testing, if the data is serially correlated, the effective degrees of freedom is reduced: if consecutive values depend on one another, then each one doesn’t provide entirely “new information.”
The limiting case helps: if \(\rho_1=1\), i.e. values are perfectly correlated, then any new value provides zero new information: it is determined entirely by the preceding value.
tanom_dt_day = pf.stats.detrend(ds_cp_day["temp_anom"])
tanom_dt_mon = pf.stats.detrend(ds_cp_mon["temp_anom"])
tanom_dt_ann = pf.stats.detrend(ds_cp_ann["temp_anom"])
acf_tanom_day = sm.tsa.acf(tanom_dt_day, fft=False, nlags=len(tanom_dt_day)-1)
acf_tanom_mon = sm.tsa.acf(tanom_dt_mon, fft=False, nlags=len(tanom_dt_mon)-1)
acf_tanom_ann = sm.tsa.acf(tanom_dt_ann, fft=False, nlags=len(tanom_dt_ann)-1)
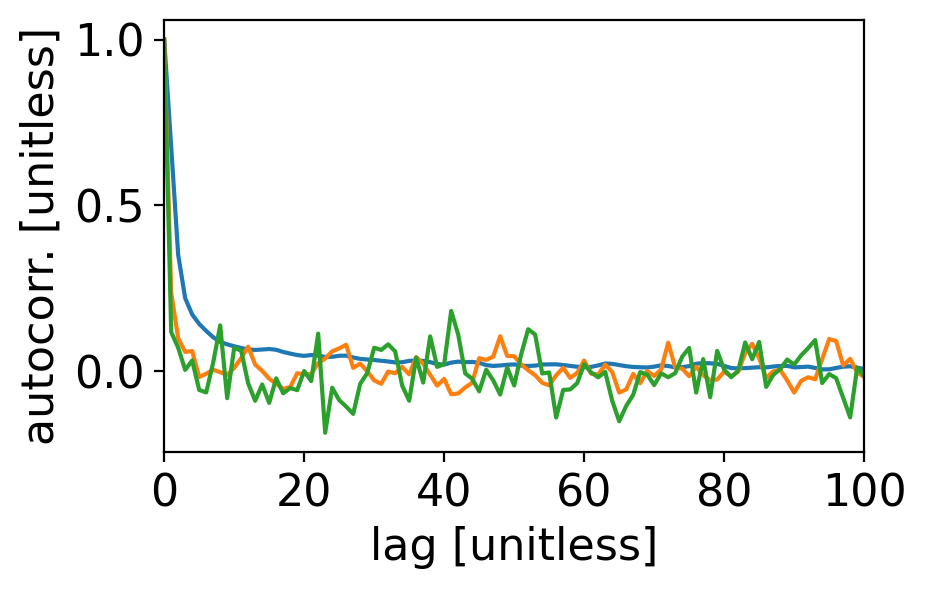
fig, ax = pplt.faceted_ax()
ax.plot(acf_tanom_day)
ax.plot(acf_tanom_mon)
ax.plot(acf_tanom_ann)
ax.set_xlabel("lag [unitless]")
ax.set_ylabel("autocorr. [unitless]")
ax.set_xlim(0, 100)
(0.0, 100.0)
def eff_sample_size(arr):
"""Effective sample size for time mean of serially correlated data.
C.f. Eq. 5.28-5.30 of Delsole and Tippett.
"""
n_raw = len(arr)
acf = sm.tsa.acf(arr, fft=False, nlags=n_raw-1)
n_sub1 = 1 + 2. * np.sum(acf[1:] * (1 - np.arange(1, n_raw) / n_raw))
return n_raw / n_sub1
eff_sample_size(ds_cp_day["temp_avg"].dropna("time"))
911.7987953404066
eff_sample_size(tanom_dt_day)
35775.09651332172
len(tanom_dt_day)
56520
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson
from scipy.stats import t
def estimate_autocorrelation(series):
# Estimate autocorrelation using statsmodels
acf = sm.tsa.acf(series, fft=False, nlags=len(series)-1)
return acf[1:] # exclude lag=0
def calculate_effective_sample_size(N, autocorrelations):
# Calculate the effective sample size
sum_autocorrelations = 2 * np.sum(autocorrelations)
ESS = N / (1 + sum_autocorrelations)
return ESS
def adjusted_t_test(series1, series2):
# Calculate autocorrelation of each series
autocorr1 = estimate_autocorrelation(series1)
autocorr2 = estimate_autocorrelation(series2)
# Calculate effective sample sizes
ESS1 = calculate_effective_sample_size(len(series1), autocorr1)
ESS2 = calculate_effective_sample_size(len(series2), autocorr2)
# Use the harmonic mean of the effective sample sizes as DOF for t-test
dof = 1 / (1/ESS1 + 1/ESS2)
# Calculate t-statistic
mean_diff = np.mean(series1) - np.mean(series2)
se_diff = np.sqrt(np.var(series1, ddof=1)/len(series1) + np.var(series2, ddof=1)/len(series2))
t_stat = mean_diff / se_diff
# Calculate two-tailed p-value
p_value = (1 - t.cdf(np.abs(t_stat), dof)) * 2
return t_stat, p_value, dof
6.4.3. Ljung-Box test for significance of serial correlation#
sm.stats.acorr_ljungbox(tanom_dt_day, return_df=True)
| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 25887.026597 | 0.0 |
| 2 | 32831.472560 | 0.0 |
| 3 | 35565.471199 | 0.0 |
| 4 | 37210.950707 | 0.0 |
| 5 | 38355.457929 | 0.0 |
| 6 | 39184.565111 | 0.0 |
| 7 | 39772.495491 | 0.0 |
| 8 | 40209.829423 | 0.0 |
| 9 | 40576.880509 | 0.0 |
| 10 | 40892.929242 | 0.0 |
sm.stats.acorr_ljungbox(tanom_dt_mon, return_df=True)
| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 104.662150 | 1.448416e-24 |
| 2 | 122.937672 | 2.015689e-27 |
| 3 | 129.141008 | 8.282917e-28 |
| 4 | 135.905960 | 2.122994e-28 |
| 5 | 136.510203 | 9.868729e-28 |
| 6 | 136.632771 | 5.144024e-27 |
| 7 | 136.662130 | 2.541612e-26 |
| 8 | 136.682984 | 1.160831e-25 |
| 9 | 136.926966 | 4.442118e-25 |
| 10 | 137.090957 | 1.661461e-24 |
sm.stats.acorr_ljungbox(tanom_dt_ann, return_df=True)
| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 2.187742 | 0.139113 |
| 2 | 2.974831 | 0.225956 |
| 3 | 2.976855 | 0.395208 |
| 4 | 3.142098 | 0.534333 |
| 5 | 3.666875 | 0.598301 |
| 6 | 4.347608 | 0.629746 |
| 7 | 4.455851 | 0.726027 |
| 8 | 7.596081 | 0.473886 |
| 9 | 8.708354 | 0.464620 |
| 10 | 9.538571 | 0.481864 |
6.5. Autocovariance and autocorrelation#
6.5.1. Sample autocovariance#
for \(\tau=0,\pm1,\pm2,\dots,\pm(N-1)\), where \(\hat\mu_t\) is the estimated deterministic component.
import numpy as np
def autocov(arr, lags=None):
"""Sample autocovariance of a 1D array.
Assumes that the deterministic component, $\hat\mu$, is constant in time.
"""
if isinstance(arr, xr.DataArray):
vals = arr.values
else:
vals = arr
num_vals = len(vals)
if lags is None:
lags = range(num_vals)
if np.isscalar(lags):
lags = [lags]
lags = np.abs(lags)
mean = np.mean(vals)
covs = np.zeros_like(lags) * np.nan
for n, lag in enumerate(lags):
x_t = vals[lag:]
x_t_lag = vals[:num_vals - lag]
covs[n] = np.sum((x_t - mean) * (x_t_lag - mean))
return covs / num_vals
6.5.2. Sample autocorrelation function#
where recall that \(\hat c(\tau)\) is the autocovariance function.
def autocorr(time_series, lags=None):
"""Sample autocorrelation function"""
acv = autocov(time_series, lags)
return acv / acv[0]
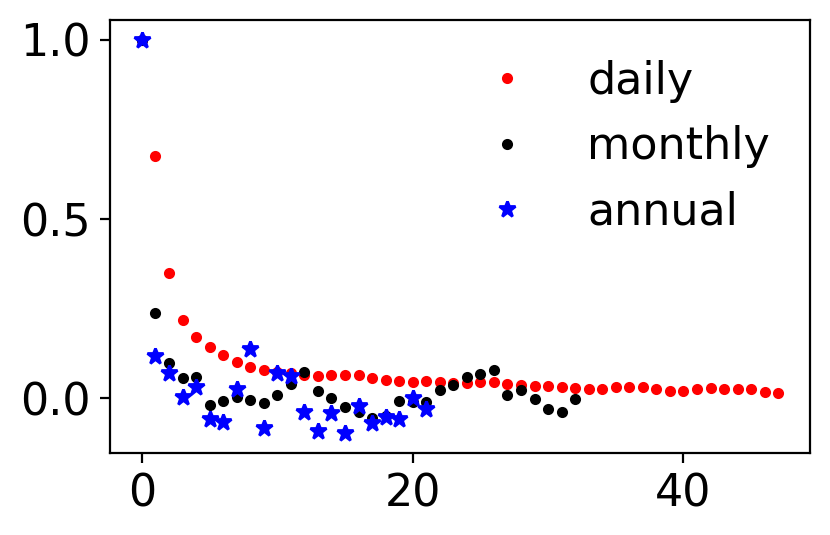
fig, ax = pplt.faceted_ax()
ax.plot(sm.tsa.acf(tanom_dt_day), ".r", label="daily")
ax.plot(sm.tsa.acf(tanom_dt_mon), ".k", label="monthly")
ax.plot(sm.tsa.acf(tanom_dt_ann), "*b", label="annual")
ax.legend(frameon=False)
<matplotlib.legend.Legend at 0x16076e7d0>
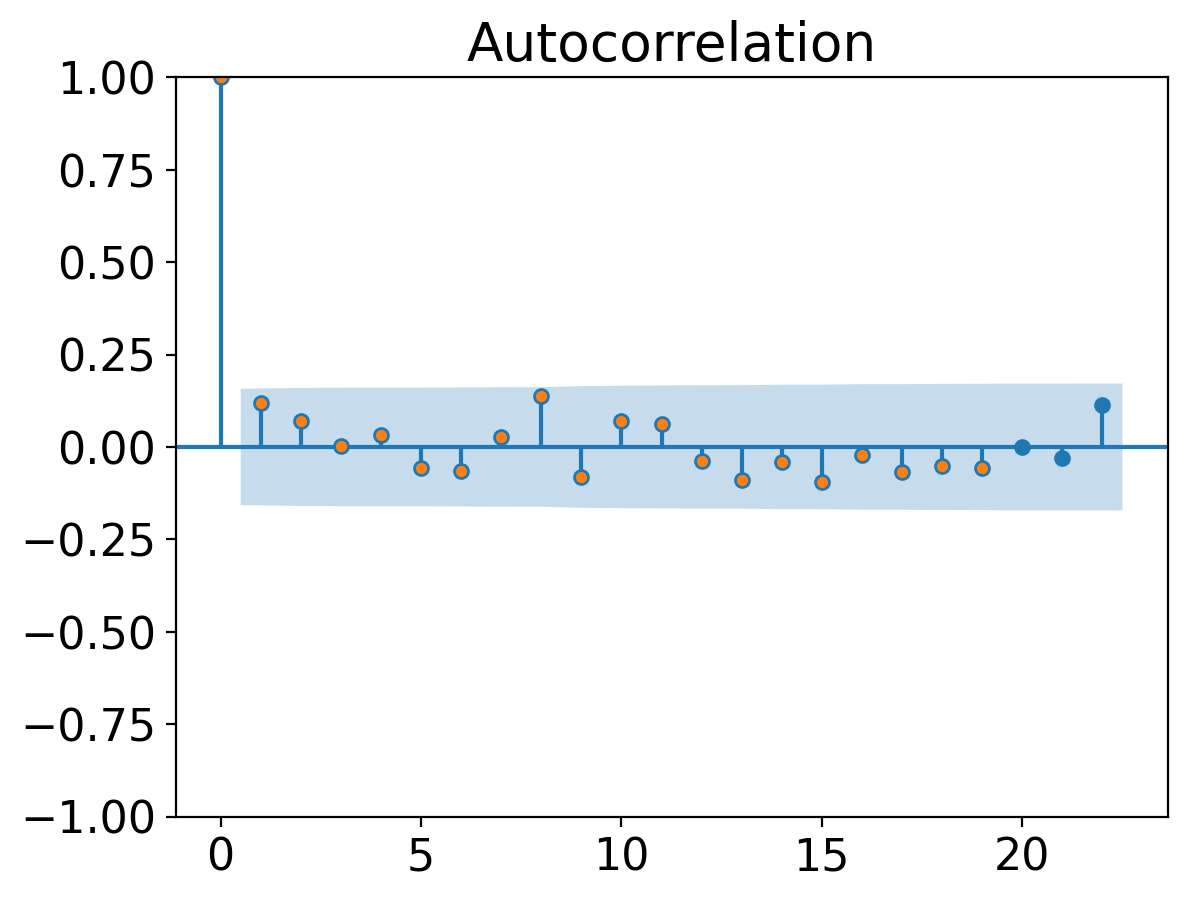
from statsmodels.graphics.tsaplots import plot_acf
_ = plot_acf(tanom_dt_ann)
plt.plot(autocorr(tanom_dt_ann.values, range(20)), ".")
[<matplotlib.lines.Line2D at 0x160c16910>]
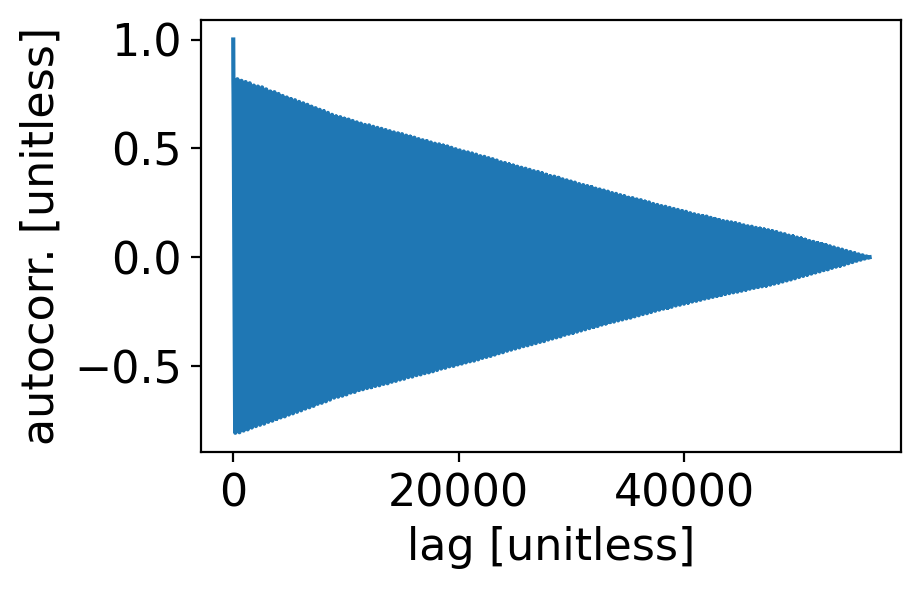
acf_tavg = sm.tsa.acf(ds_cp_day["temp_avg"].dropna("time"), fft=False, nlags=len(ds_cp_day["temp_avg"].dropna("time"))-1)
fig, ax = pplt.faceted_ax()
ax.plot(acf_tavg)
ax.set_xlabel("lag [unitless]")
ax.set_ylabel("autocorr. [unitless]")
Text(0, 0.5, 'autocorr. [unitless]')
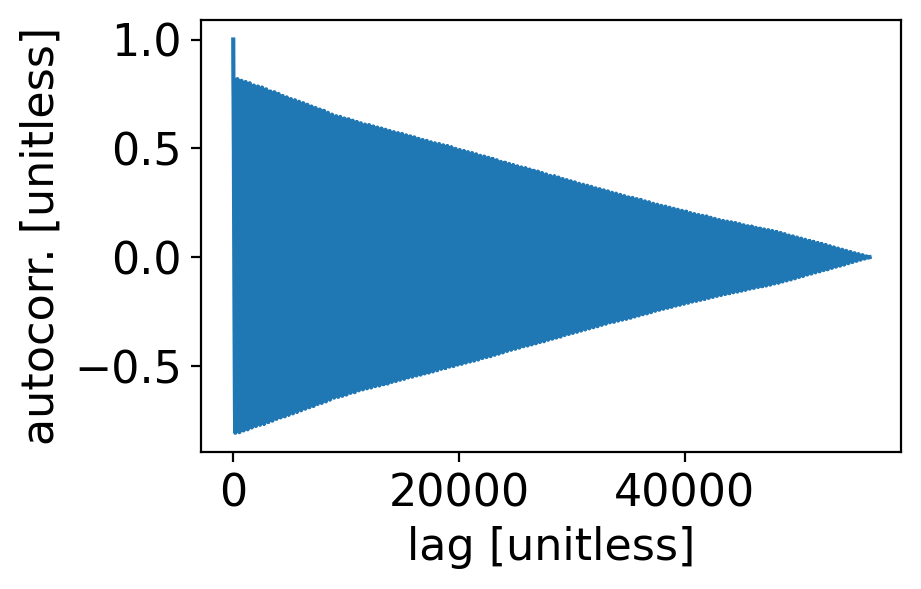
ds_cp_day_noleap = ds_cp_day.where(~((ds_cp_day.time.dt.month == 2) & (ds_cp_day.time.dt.day == 29)), drop=True)
acf_tavg_noleap = sm.tsa.acf(ds_cp_day_noleap["temp_avg"].dropna("time"), fft=False, nlags=len(ds_cp_day_noleap["temp_avg"].dropna("time"))-1)
fig, ax = pplt.faceted_ax()
ax.plot(acf_tavg_noleap)
ax.set_xlabel("lag [unitless]")
ax.set_ylabel("autocorr. [unitless]")
Text(0, 0.5, 'autocorr. [unitless]')
6.6. White noise processes#
In a white noise process, the distribution at each timestep is independent of the distributions at all other timesteps.
In other words, every time step is randomly drawn without any influence from the values of any preceding timesteps.
In turn, the value drawn at a given timestep has no influence on that of any subsequent timesteps.
This contrasts with many physical processes, where through e.g. a conservation law the value now depends very much on the value immediately before.
In stationary white noise, not only is each timestep independent, but the distribution being drawn from at each timestep is identical across timesteps.
Whereas if the distribution varies across timesteps in any way—but the draw at each timestep remains independent from those of any others—the process is nonstationary white noise.
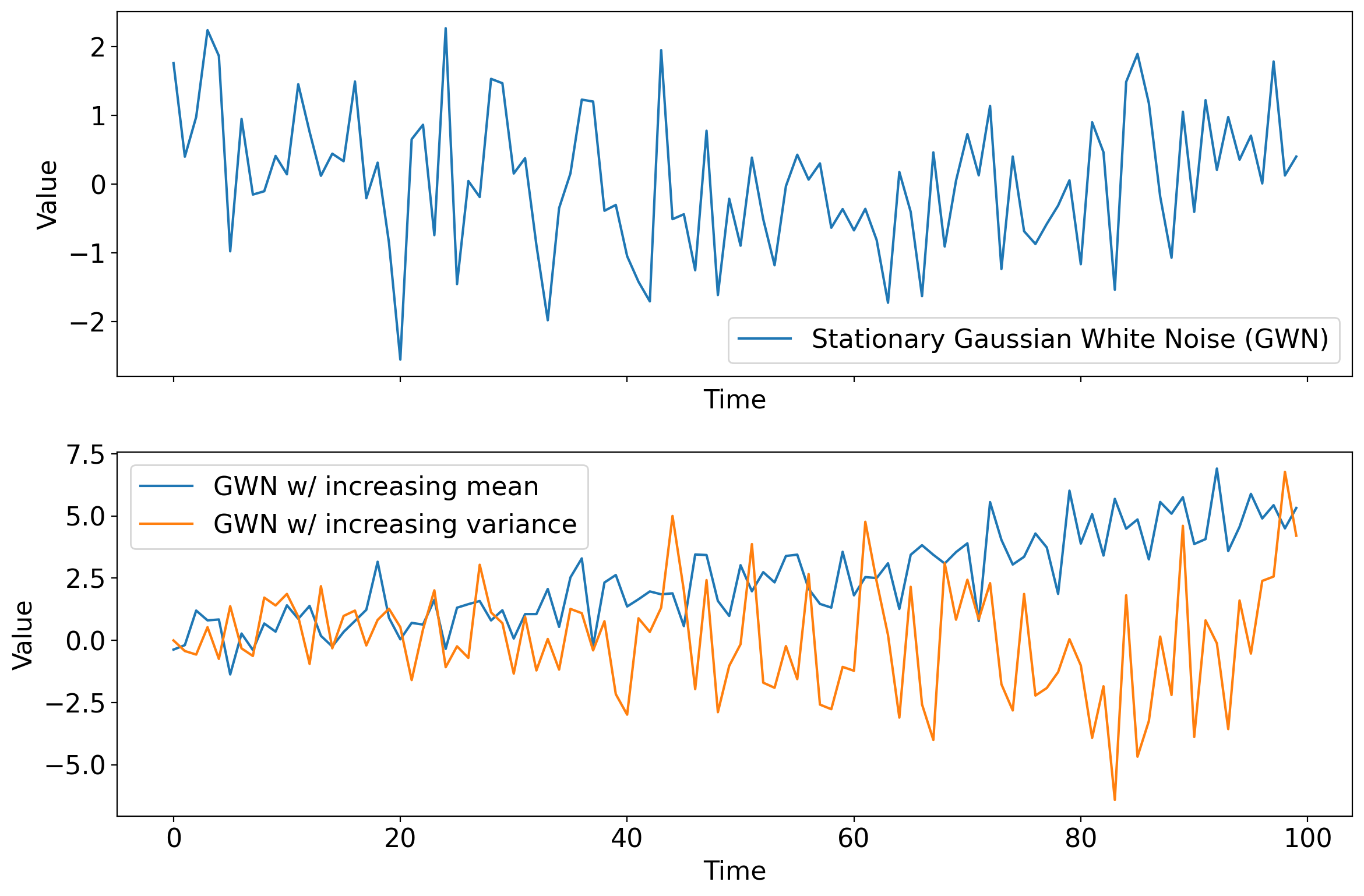
Arguably the most important white noise process is one that draws from the normal distribution: Gaussian white noise (GWN).
Next: timeseries generated from one stationary and two non-stationary GWN processes.
import matplotlib.pyplot as plt
import numpy as np
# Generate stationary Gaussian white noise
np.random.seed(0)
stationary_time_series = np.random.normal(loc=0.0, scale=1.0, size=100)
# Generate non-stationary Gaussian white noise with growing variance
time = np.arange(100)
growing_variance = 0.1 * time # Variance grows over time
ts_inc_var = np.random.normal(loc=0.0, scale=np.sqrt(growing_variance))
# Generate non-stationary Gaussian white noise with growing variance
time = np.arange(100)
growing_mean = 0.05 * time # Variance grows over time
ts_inc_mean = np.random.normal(loc=growing_mean, scale=1)
# Create the plot
fig, axs = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
# Plot the stationary time series
axs[0].plot(stationary_time_series, label='Stationary Gaussian White Noise (GWN)')
axs[0].legend()
# Plot the non-stationary time series
axs[1].plot(ts_inc_mean, label='GWN w/ increasing mean')
axs[1].legend()
axs[1].plot(ts_inc_var, label='GWN w/ increasing variance')
axs[1].legend()
# Set common labels
for ax in axs:
ax.set_xlabel('Time')
ax.set_ylabel('Value')
plt.tight_layout()
plt.show()
6.7. Autoregressive models#
In autoregressive models (often referred to as AR models), the value at each timestep is set by those before, plus noise. Specifically, the value at a given timestep is determined by some linear combination of one or more previous timesteps, plus white noise.
The simplest autoregressive model is the 1st order autoregressive model, or AR(1) for short.
6.7.1. AR(1): 1st order autoregressive#
6.7.1.1. The model#
An AR(1) process, denoted here as \(X\), is given by
where \(X_t\) is the value at time \(t\), \(\phi\) is a constant, \(X_{t-1}\) is the value at the preceding time, \(W_t\) is a white noise process, and \(k\) is a constant.
6.7.1.2. Connection to dynamical systems#
The laws of physics and thermodynamics usually take the following form:
where \(a\) is some constant (usually negative, indicating a damping).
We can rearrange the AR(1) equation above to resemble a discretized verison of this general form. Subtract \(X_{t-1}\) from both sides and divide by the time spacing between consecutive points, which we’ll denote \(\delta t\). Then we have
having defined \(a\equiv(\phi - 1)/\delta t\), \(\tilde{W}_t\equiv W_t/\delta t\), and \(\tilde{k}\equiv k/\delta t\).
The \(\tilde{k}\) term is analogous to the forcing, and the \(\tilde{W}_t\) term is the noise.
Finally, recall from calculus that the left-hand side is the discrete approximation to a derivative, which becomes increasingly accurate as the timestep becomes smaller:
6.7.1.3. The first timestep#
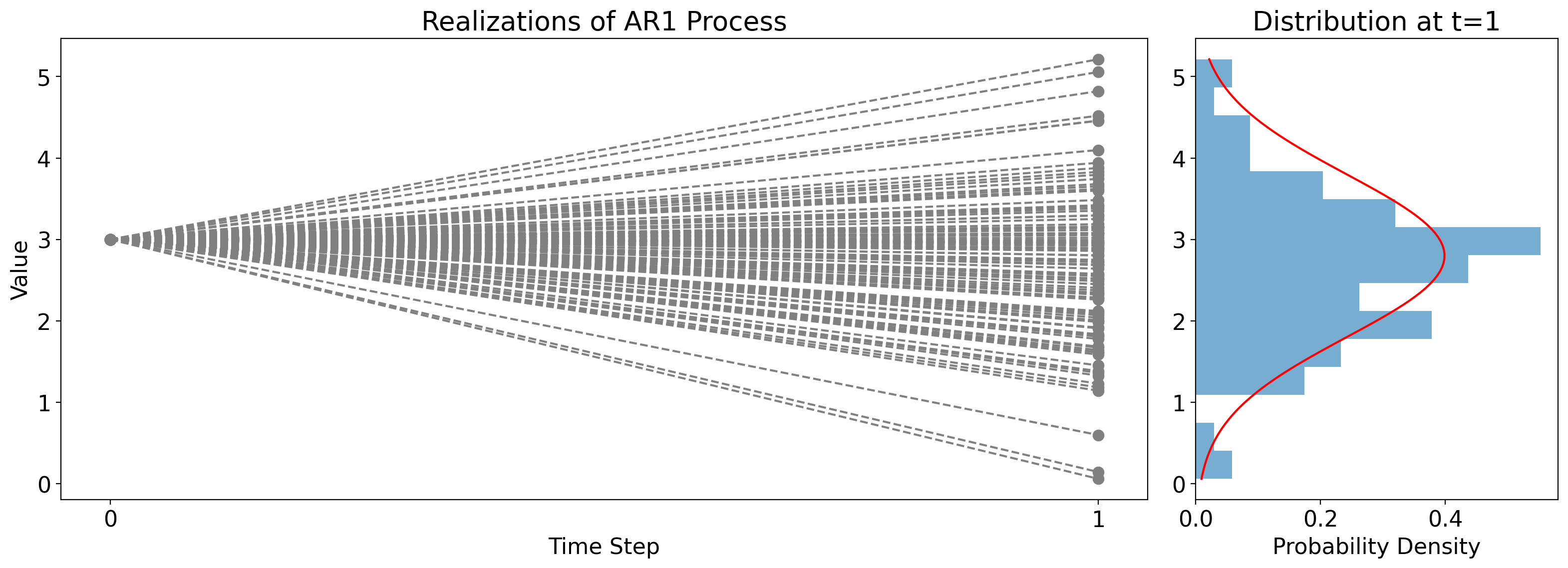
If at the initial time \(t=0\) this process has the value \(x_0\), then the value after one timestep, at \(t=1\), is
This is the sum of a constant (\(\phi x_0+k\)) and a random draw from a Gaussian, \(W_1\). That means we can’t know the value \(X_1\) exactly. But we can determine its probability distribution.
The Gaussian has zero mean and variance \(\sigma^2_W\), and so the resulting conditional distribution is:
In other words, given that the value at \(t=0\) is \(x_0\), the distribution of \(x_1\) is normally distributed with mean \(\phi x_0+k\) and variance \(\sigma^2_W\).
To illustrate this, the figure below shows many independent realizations of an AR(1) process. Across all cases, the constants \(\phi\), \(k\), and \(\sigma^2_W\) do not differ, and they also all start from the same initial condition \(x_0\).
But the random draw \(W_1\) is different across the cases, leading to different values at \(t_1\) across them.
The panel on the right shows the corresponding histogram in the bars, along with the actual PDF, \(\mathcal{N}(\phi x_0+k, \sigma^2_W)\), in red.
# Parameters
mu = 1 # Constant term
alpha = 0.6 # Autoregressive coefficient
sigma = 1 # Standard deviation of the white noise
num_realizations = 100 # Number of realizations
num_timesteps = 2 # Only two timesteps
# Generating realizations for two timesteps
realizations = np.zeros((num_realizations, num_timesteps))
for i in range(num_realizations):
epsilon = np.random.normal(0, sigma, num_timesteps) # White noise
realizations[i, 0] = 3 # Initial value at t=0
realizations[i, 1] = mu + alpha * realizations[i, 0] + epsilon[1]
# Extracting values at t=1 for histogram and PDF
X_t = realizations[:, 1]
# Analytical PDF for X_t
pdf_x = np.linspace(min(X_t), max(X_t), 100)
pdf_y = scipy.stats.norm.pdf(pdf_x, mu + alpha * realizations[i, 0], sigma)
# Plotting
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6), gridspec_kw={'width_ratios': [3, 1]})
# Time series plot
for i in range(num_realizations):
ax1.plot(range(num_timesteps), realizations[i], color='grey', linestyle="--", marker=".", markersize=15)
ax1.set_xlabel('Time Step')
ax1.set_ylabel('Value')
ax1.set_title('Realizations of AR1 Process')
ax1.set_xticks(range(num_timesteps))
#ax1.grid(True)
# Rotated histogram and PDF
ax2.hist(X_t, bins=15, orientation='horizontal', density=True, alpha=0.6)
ax2.plot(pdf_y, pdf_x, 'r-')
ax2.set_xlabel('Probability Density')
ax2.set_title('Distribution at t=1')
#ax2.grid(True)
plt.tight_layout()
plt.show()
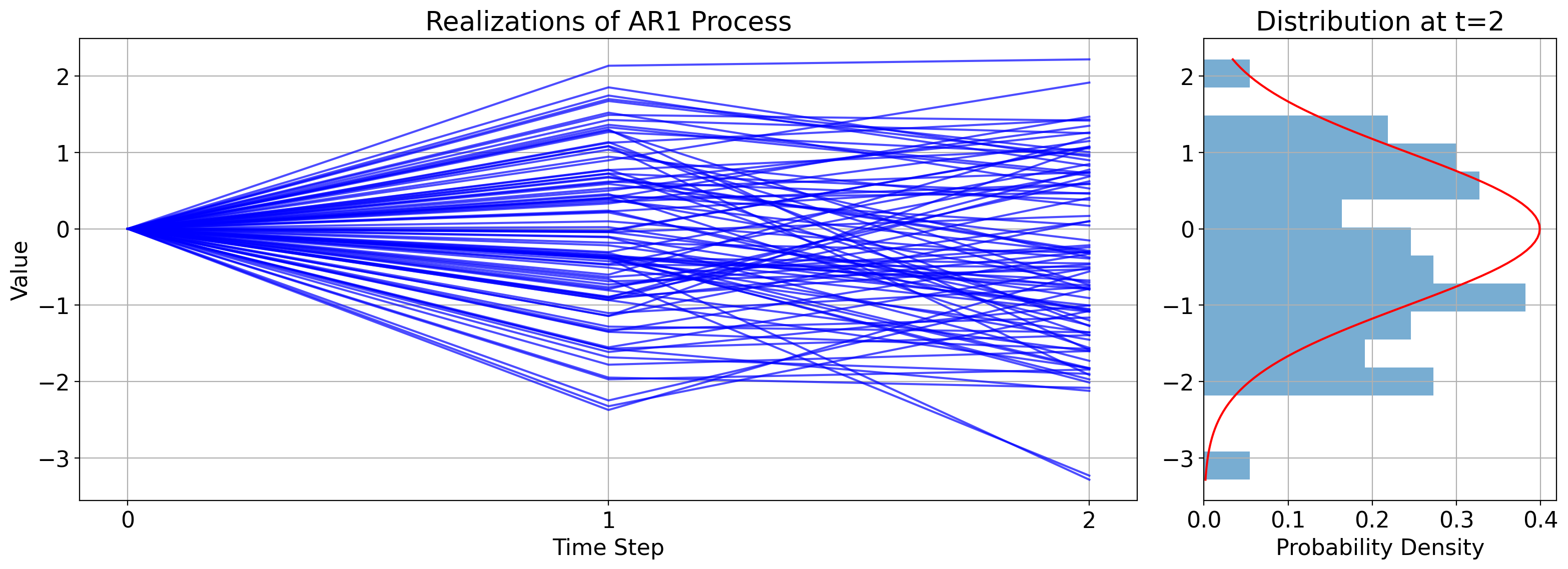
6.7.1.4. The second timestep#
Now let’s advance another timestep to \(t=2\). Plugging everything in gives:
The first equality is by definition, the second equality comes from plugging in the value we derived above of \(x_1\), and the last is just rearranging term.
Similar to the value at the first timestep, this is the sum of a constant, \(\phi^2x_0+(1+\phi)k\), and Gaussian noise, \(W_2+\phi W_1\).
(This is true because, in general, the sum of independent draws from two Gaussians is itself Gaussian with variance equal to the sum of the variances of the two Guassians.)
As such, the conditional distribution is:
Here’s the corresponding illustration:
# Parameters
mu = 0 # Constant mean term
alpha = 0.6 # Autoregressive coefficient
sigma = 1 # Standard deviation of the white noise
num_realizations = 100 # Number of realizations
num_timesteps = 3 # Three timesteps
# Generating realizations for three timesteps
realizations = np.zeros((num_realizations, num_timesteps))
for i in range(num_realizations):
epsilon = np.random.normal(0, sigma, num_timesteps) # White noise
realizations[i, 0] = mu # Initial value at t=0
for t in range(1, num_timesteps):
realizations[i, t] = mu + alpha * (realizations[i, t-1] - mu) + epsilon[t]
# Extracting values at t=2 for histogram and PDF
X_t = realizations[:, 2]
# Analytical PDF for X_t at t=2
pdf_x_t2 = np.linspace(min(X_t), max(X_t), 100)
pdf_y_t2 = scipy.stats.norm.pdf(pdf_x_t2, mu + alpha * (mu + alpha * (mu - mu) - mu), sigma)
# Plotting
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6), gridspec_kw={'width_ratios': [3, 1]})
# Time series plot
for i in range(num_realizations):
ax1.plot(range(num_timesteps), realizations[i], color='blue', alpha=0.7)
ax1.set_xlabel('Time Step')
ax1.set_ylabel('Value')
ax1.set_title('Realizations of AR1 Process')
ax1.set_xticks(range(num_timesteps))
ax1.grid(True)
# Rotated histogram and PDF at t=2
ax2.hist(X_t, bins=15, orientation='horizontal', density=True, alpha=0.6)
ax2.plot(pdf_y_t2, pdf_x_t2, 'r-')
ax2.set_xlabel('Probability Density')
ax2.set_title('Distribution at t=2')
ax2.grid(True)
plt.tight_layout()
plt.show()
6.7.1.5. Beyond the second timestep (i.e. the general solution)#
These steps can be repeated indefinitely, leading to (skipping over the details) the following general expression for the conditional distribution at a given time \(t\) given the initial value \(x_0\):
We can find the asymptotic or limiting solution to this by letting time go to infinity.
It’s always the case that \(|\phi|<1\), otherwise the model blows up.
As such, as \(t\) increases \(\phi^t\) gets smaller and smaller, such that the \(\phi^t x_0\) term vanishes, the \(1-\phi^t\) term becomes just \(1\), and similarly the \(1-\phi^{2t}\) term becomes just \(1\) also.
Thus, we have:
In words, given enough time the distribution becomes approximately a Gaussian with mean \(k/(1-\phi)\) and variance \(\sigma^2_W/(1-\phi^2)\).
Notice something cool here: \(x_0\) doesn’t show up at all!
This asymptotic solution is the same no matter what the initial value was.
Whether the initial value was originally very close to \(k/(1-\phi)\) or very far from it, the AR(1) process moves (so to speak) toward the same distribution determined by the constant \(k\) and the strength of the coupling between consecutive timesteps, \(\phi\).
Next let’s see the corresponding plot:
# Parameters
alpha = 0.6 # Autoregressive coefficient
sigma = 1 # Standard deviation of the white noise
k = 0.5 # Constant term
x0 = -1 # initial value
num_realizations = 100 # Number of realizations
num_timesteps = 10 # Ten timesteps
# Generating realizations for ten timesteps with the new model
realizations = np.zeros((num_realizations, num_timesteps))
for i in range(num_realizations):
epsilon = np.random.normal(0, sigma, num_timesteps) # White noise
realizations[i, 0] = x0
for t in range(1, num_timesteps):
realizations[i, t] = alpha * realizations[i, t-1] + epsilon[t] + k
# Extracting values at t=9 for histogram and PDF
X_t = realizations[:, -1] # Last timestep
# Analytical PDF for X_t at t=9
pdf_x_t9 = np.linspace(min(X_t), max(X_t), 100)
# Mean for the PDF considering the cumulative effect of alpha and k over timesteps
mean_t9 = k * (1 - alpha ** num_timesteps) / (1 - alpha)
pdf_y_t9 = scipy.stats.norm.pdf(pdf_x_t9, mean_t9, sigma)
# Plotting
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6), gridspec_kw={'width_ratios': [3, 1]})
# Time series plot
for i in range(num_realizations):
ax1.plot(range(num_timesteps), realizations[i], color='blue', alpha=0.7)
ax1.set_xlabel('Time Step')
ax1.set_ylabel('Value')
ax1.set_title('Realizations of AR1 Process with Constant Term k')
ax1.set_xticks(range(num_timesteps))
ax1.grid(True)
# Rotated histogram and PDF at t=9
ax2.hist(X_t, bins=15, orientation='horizontal', density=True, alpha=0.6)
ax2.plot(pdf_y_t9, pdf_x_t9, 'r-')
ax2.set_xlabel('Probability Density')
ax2.set_title('Distribution at t=9')
ax2.grid(True)
plt.tight_layout()
plt.show()
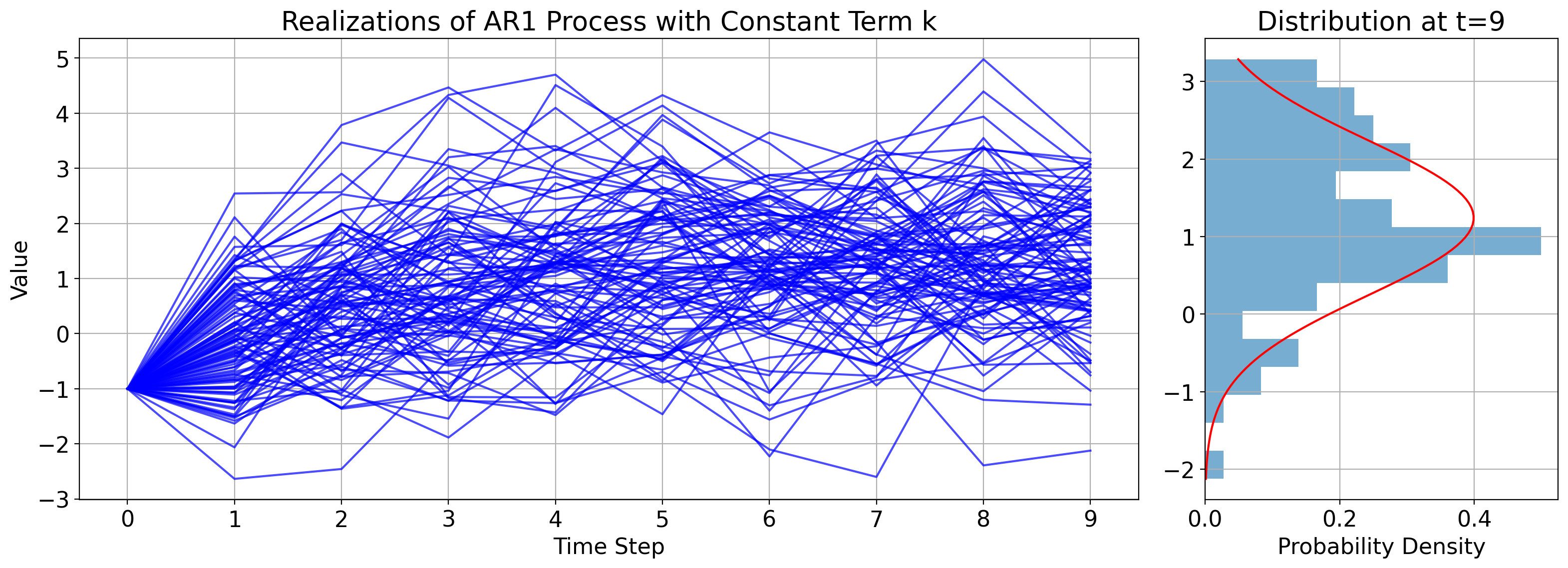
6.7.1.6. Autocorrelation function of an AR(1) process#
This is simply
Since \(0<\phi<1\), the autocorrelation becomes smaller in magnitude as the lag increases in either direction.
import numpy as np
import holoviews as hv
import panel as pn
from statsmodels.tsa.arima_process import ArmaProcess
from statsmodels.tsa.stattools import acf
hv.extension('bokeh')
# Function to generate an AR(1) process and its ACF
def generate_ar1_process(phi, size=150):
# Define AR(1) process with no MA component
ar = np.array([1, -phi])
ma = np.array([1])
AR_object = ArmaProcess(ar, ma)
return AR_object.generate_sample(nsample=size)
# Function to calculate the ACF of the time series
def calculate_acf(time_series, nlags=40):
acf_vals = acf(time_series, nlags=nlags, fft=False)
return acf_vals
# Create the interactive plot
def interactive_plot(phi):
# Generate the time series
time_series = generate_ar1_process(phi)
# Calculate the empirical ACF
acf_values = calculate_acf(time_series, nlags=40)
lags = np.arange(len(acf_values))
# Calculate the theoretical ACF for an AR(1) process
theoretical_acf = [phi**k for k in lags]
# Create the Holoviews plots
ts_plot = hv.Curve(time_series).opts(
width=400, height=400, title=f"AR(1) Time Series with phi={phi}",
tools=['hover'])
acf_plot = hv.Curve((lags, acf_values)).opts(
width=400, height=400, title="ACF", ylim=(-1, 1), xlim=(0, 40),
tools=['hover'])
# Overlay the theoretical ACF on the empirical ACF plot
theoretical_acf_plot = hv.Curve((lags, theoretical_acf)).opts(
line_dash='dotted', color='red')
acf_combined = acf_plot * theoretical_acf_plot
# Combine the time series plot and the combined ACF plot into a layout without linking the axes
layout = (ts_plot + acf_combined).opts(shared_axes=False).cols(2)
return layout
# Slider for the phi coefficient
phi_slider = pn.widgets.FloatSlider(name='Autocorrelation Coefficient (phi)', start=-0.99, end=0.99, step=0.01, value=0.5)
# Interactive function to update plot based on slider value
@pn.depends(phi=phi_slider)
def update_plot(phi):
return interactive_plot(phi)
# Panel layout
pn.Column(
pn.Row(phi_slider),
update_plot
).servable()
/Users/sah2249/miniconda3/envs/stat-methods-course/lib/python3.11/site-packages/holoviews/plotting/bokeh/plot.py:987: UserWarning: found multiple competing values for 'toolbar.active_drag' property; using the latest value
layout_plot = gridplot(
/Users/sah2249/miniconda3/envs/stat-methods-course/lib/python3.11/site-packages/holoviews/plotting/bokeh/plot.py:987: UserWarning: found multiple competing values for 'toolbar.active_scroll' property; using the latest value
layout_plot = gridplot(
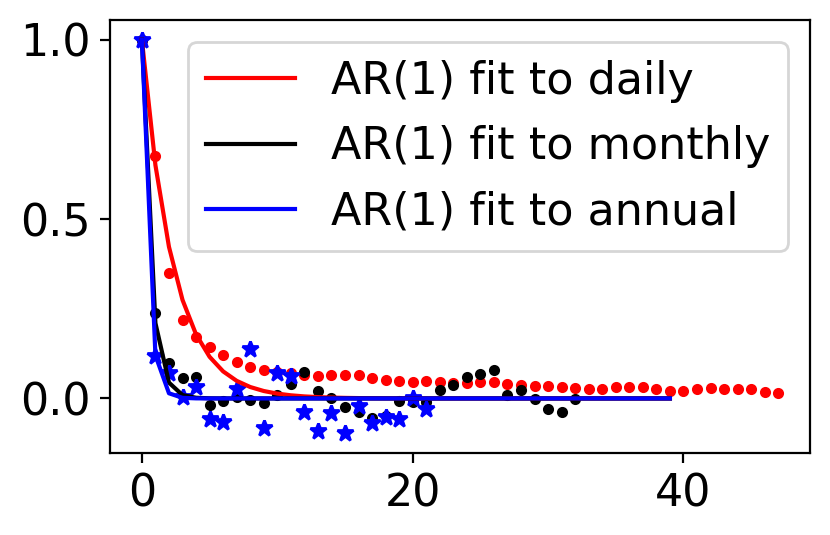
6.7.1.7. Example: AR(1) fitted to Central Park temperature anomalies#
fig, ax = pplt.faceted_ax()
ax.plot(sm.tsa.acf(tanom_dt_day), ".r")
ax.plot(sm.tsa.acf(tanom_dt_mon), ".k")
ax.plot(sm.tsa.acf(tanom_dt_ann), "*b")
ax.plot(np.arange(40), 0.65 ** np.arange(40), "-r", label="AR(1) fit to daily")
ax.plot(np.arange(40), 0.21 ** np.arange(40), "-k", label="AR(1) fit to monthly")
ax.plot(np.arange(40), 0.12 ** np.arange(40), "-b", label="AR(1) fit to annual")
ax.legend()
<matplotlib.legend.Legend at 0x160f78e90>
6.7.2. AR(2): 2nd order autoregressive model#
The AR(1) model depends only on the immediately preceding value.
The AR(2) model depends on that value and the one before that, i.e on the two most recent values.
But otherwise it is formulated in just the same way as the AR(1) model.
Formally:
where \(\phi_1\) and \(\phi_2\) are both constants.
Next is an interactive plot that generates timeseries for an AR(2) process with values of \(\phi_1\) and \(\phi_2\) of your choosing:
# Function to generate an AR(2) process
def generate_ar2_process(phi1, phi2, size=100):
# Define AR(2) process with no MA component
ar = np.array([1, -phi1, -phi2])
ma = np.array([1])
AR_object = ArmaProcess(ar, ma)
return AR_object.generate_sample(nsample=size)
# Create the interactive plot
def interactive_autocorrelation(phi1, phi2):
time_series = generate_ar2_process(phi1, phi2)
acf_values = acf(time_series, nlags=40, fft=False)
ts_plot = hv.Curve(time_series).opts(
width=400, height=400, title=f"AR(2) Time Series with phi1={phi1}, phi2={phi2}", tools=["hover"])
acf_plot = hv.Curve((list(range(len(acf_values))), acf_values)).opts(
width=400, height=400, title="ACF", ylim=(-1, 1), xlim=(0, 40), tools=["hover"])
layout = (ts_plot + acf_plot).opts(shared_axes=False).cols(2)
return layout
# Sliders for the phi coefficients
phi1_slider = pn.widgets.FloatSlider(name='Autocorrelation Coefficient (phi1)', start=-0.99, end=0.99, step=0.01, value=0.5)
phi2_slider = pn.widgets.FloatSlider(name='Autocorrelation Coefficient (phi2)', start=-0.99, end=0.99, step=0.01, value=-0.5)
# Interactive function to update plot based on slider values
@pn.depends(phi1=phi1_slider, phi2=phi2_slider)
def update_plot(phi1, phi2):
return interactive_autocorrelation(phi1, phi2)
# Panel layout
pn.Column(
pn.Row(phi1_slider, phi2_slider),
update_plot
).servable()
/Users/sah2249/miniconda3/envs/stat-methods-course/lib/python3.11/site-packages/holoviews/plotting/bokeh/plot.py:987: UserWarning: found multiple competing values for 'toolbar.active_drag' property; using the latest value
layout_plot = gridplot(
/Users/sah2249/miniconda3/envs/stat-methods-course/lib/python3.11/site-packages/holoviews/plotting/bokeh/plot.py:987: UserWarning: found multiple competing values for 'toolbar.active_scroll' property; using the latest value
layout_plot = gridplot(
model_tanom_day_ar2 = sm.tsa.ARIMA(tanom_dt_day.values, order=(2, 0, 0))
tanom_day_ar2 = model_tanom_day_ar2.fit()
model_tanom_day_ar3 = sm.tsa.ARIMA(tanom_dt_day.values, order=(3, 0, 0))
tanom_day_ar3 = model_tanom_day_ar3.fit()
acf_tanom_day_ar2 = ArmaProcess(np.r_[1, -tanom_day_ar2.arparams], ma=np.array([1])).acf(lags=30)
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf
# Assuming 'ts' is your time series data as a numpy array or a pandas series
# Ensure that 'ts' is stationary before fitting the AR(2) model
# Fit an AR(2) model
ar_model = sm.tsa.ARIMA(tanom_dt_day.values, order=(2, 0, 0))
ar_result = ar_model.fit()
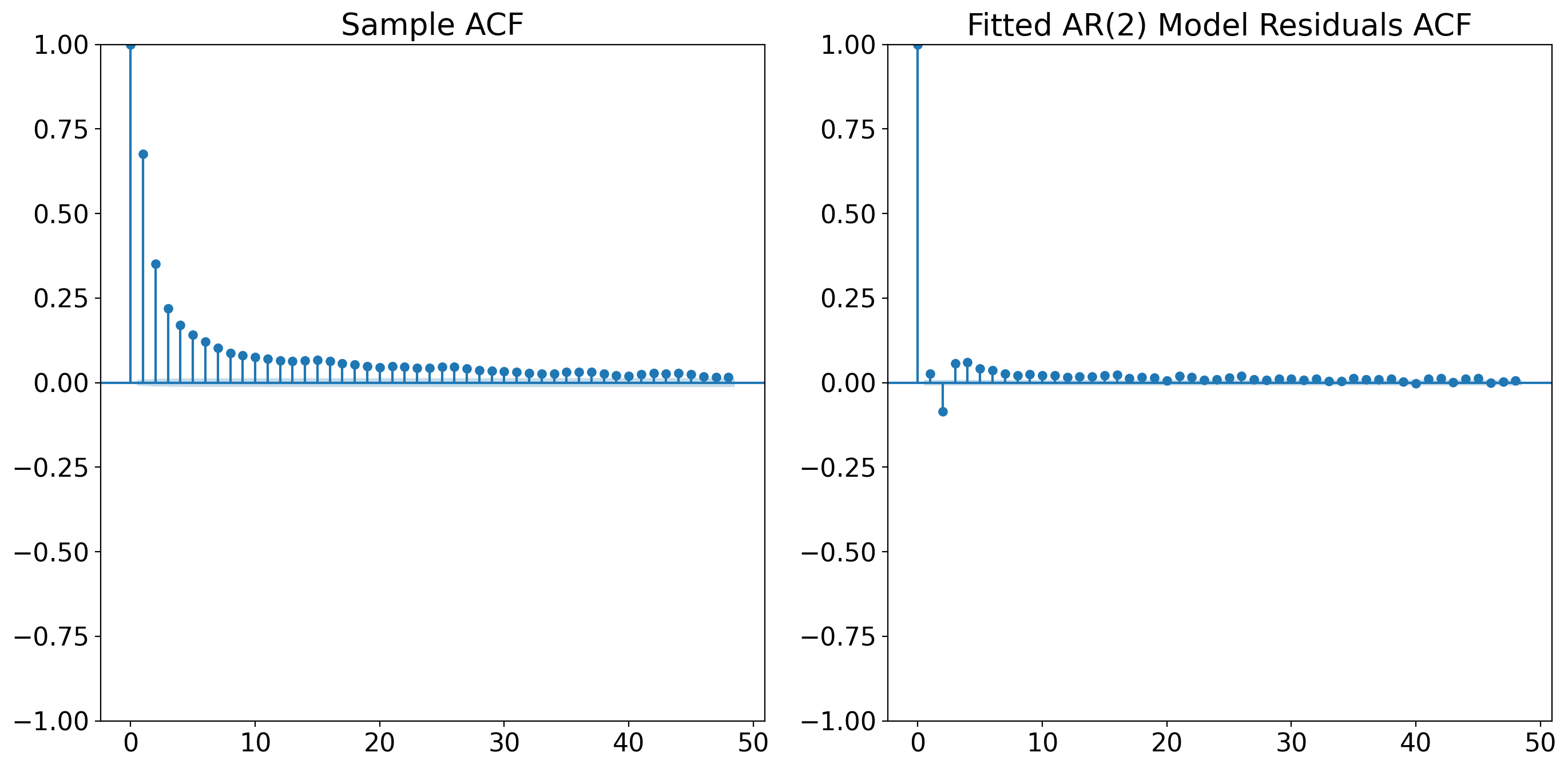
# Plot the sample ACF of the original time series data
plt.figure(figsize=(14, 7))
plt.subplot(121)
plot_acf(tanom_dt_day.values, ax=plt.gca(), title='Sample ACF')
# Plot the ACF of the residuals from the AR(2) model
residuals = ar_result.resid
plt.subplot(122)
plot_acf(residuals, ax=plt.gca(), title='Fitted AR(2) Model Residuals ACF')
plt.tight_layout()
plt.show()